Top 10 Deep Web Search Engines of 2024
When we have to search for something on the Internet, our mind, by default, goes to Google or Bing. Our mind is tuned, and we get the results we seek. But how often do we consider that the information we are looking for might be available on the deep web?
Major search engines keep meticulous details of our movement on the Internet. Well, if you don’t want Google to know about your online searches and activities, it is best to keep anonymity.
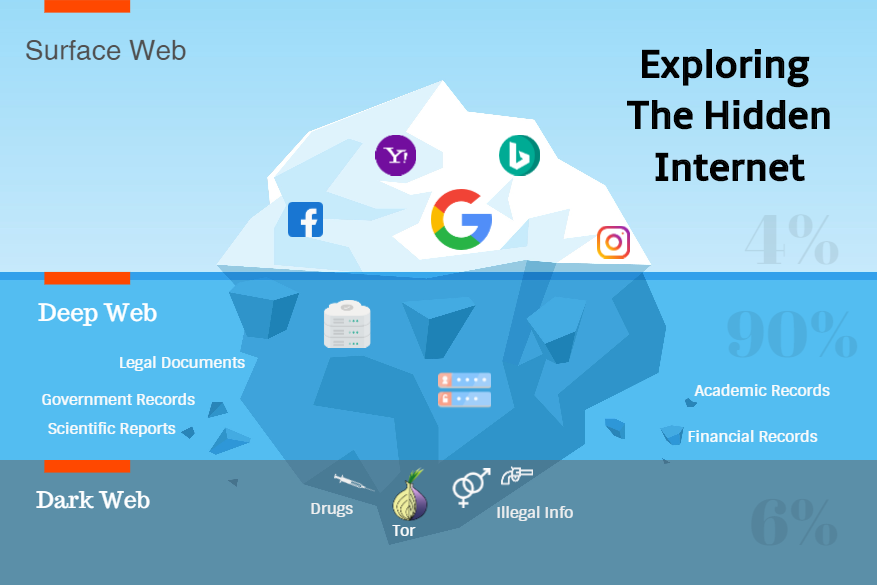
What about those enormous databases of content lying in the repository of the ‘Invisible Web,’ popularly known as the ‘Deep Web,’ which the general crawlers cannot reach? How do you get them?
Deep web content is believed to be about 500 times bigger than regular search content, and it mostly goes unnoticed by traditional search engines. When you look at the typical search engine performs a generic search. For example, there are huge personal profiles and records of people-related documents on static websites, and this high-quality content is invisible to search engines.
Why is a Deep Web search not available from Google?
The primary reason Google doesn’t provide deep web content is that this content doesn’t index in the regular search engines. Hence, these search engines will not show results or crawl to a document or file unindexed by the world wide web. The content lies behind the HTML forms. Regular search engines crawl, and the searches are derived from interconnected servers.
Interconnected servers mean you are regularly interacting with the source, but when it comes to the dark web, this does not happen. Everything is behind the veil and stays hidden internally on the Tor network, which ensures security and privacy.
Only 4 percent of Internet content is visible to the general public, and the other 96 percent is hidden behind the deep web.
Why Google is not picking up this data, or why deep web content does not get indexed, is not a secret. It is mainly that these businesses are either illegal or harmful to society at large. The content can be porn, drugs, weapons, military information, hacking tools, etc.
Robots Exclusion
The robot.txt that we usually use tells the website which files it should record and register to be indexed.
Now we have a terminology called ‘robots Exclusion files.’ Web administrators will tweak the setup so that certain pages will not appear for indexing and will remain hidden when the crawlers search.
Look at some of the crawlers that go deep into the Internet.
List of Best Deep Web Search Engines of 2024
- MyLife
- Pipl
- Yippy
- SurfWax
- Wayback Machine
- Google Scholar
- DuckDuckGo
- Fazzle
- Not Evil
- Start Page
Pipl
This is one of the search engines that will help you dig deep and get the results that may be missing on Google and Bing. Pipl robots interact with searchable databases and extract facts, contact details and other relevant information from personal profiles, member directories, scientific publications, court records and numerous other deep-web sources.
Pipl works by extracting files as it communicates with the searchable database. It attempts to get information about search queries from personal profiles and member directories, which can be highly sensitive. Pipl can deeply penetrate and get the information the user seeks. They use advanced ranking algorithms and language analysis to bring you the results closest to your keyword.
MyLife
My life engine can get you the details of a person, viz-a-viz personal data and profiles, age, occupation, residence, contact details etc. It also includes pictures and other relevant history of the person’s latest trip, and other surveys are conducted. Moreover, you can rate individuals based on their profiles and information.
Almost everyone above 18 years old in the United States has a profile on the Internet so one can expect more than 200 million profiles with rich data on MyLife searches.
Yippy
Yippy is a Metasearch Engine (it gets its outcomes by utilizing other web indexes); I’ve included Yippy here as it has a place with an entryway of devices a web client might be occupied with, for example, such as email, games, videos and so on.
The best thing about Yippy is that it doesn’t store users’ information like Google. It is a Metasearch Engine and depends on other web indexes to show its results.
Yippy may not be a good search engine for people who are used to Google because this engine searches the web differently. If you search “marijuana,” for example, it will bring up results that will read ‘the effects of marijuana” rather than a Wikipedia page and news stories. It’s a helpful website that can be good for people who want their wards to know what is required and not the other way around.
SurfWax
SurfWax is a subscription-based search engine. It has a bunch of features apart from contemporary search habits. According to the website, the name SurfWax arose because “On waves, surf wax helps surfers grip their surfboard; for Web surfing, SurfWax helps you get the best grip on information — providing the ‘best use of relevant search results.” SurfWax can integrate relevant search based with key finding elements for an effective search result.
Wayback Machine
This engine gives you enormous access to the URL information. It is the front end of the Internet Archive of open web pages. Internet Archive allows the public to post their digital documents, which can be downloaded to its data cluster. The majority of the data is collected by the web crawlers of Wayback machines automatically. The primary intention of this is to preserve public web information.
Google Scholar
Another Google search engine, but quite different from its prime engine, Google Scholar scans for a wide range of academic literature. The search results draw from university repositories, online journals, and other related web sources.
Google Scholar helps researchers find sources that exist on the Internet. You can customize your search results to a particular field of interest, region, or institution, for example, ‘psychology at Harvard University.’ This will give you access to relevant documents.
DuckDuckGo
Unlike Google, this search engine does not track your activities, which is the first good thing about it. This has a clean UI, it is simple, and yes, it can deep search the Internet.
You can customize the searches and enhance them according to the results and satisfaction. Search engines believe in quality and not quantity. The emphasis is on the best results. It does this from over 500 independent sources, including Google, Yahoo, Bing, and all the other popular search engines.
Fazzle
Accessible in English, French, and Dutch, this is a meta web index engine. It is designed to get quick results. The query items include Images, Documents, Video, Audio, Shopping, Whitepaper and more.
Fazzle lists most items that may look like promotions and like to know meta web indexes available; this search engine does not cover supported connections in searches. So the first search results on any keyword could likely be a promotion. Nevertheless, the Deep Web Fazzle stands apart when giving you the best pick on searches.
Not Evil
The not-for-profit ‘not Evil’ search engines entirely survive on contribution, and it seems to be getting a fair share of support. Highly reliable in the search results, this SE has a highly competitive functionality in the TOR network.
There is no advertising or tracking, and intelligent and continuously updated search algorithms make it easy to find the necessary goods, content or information. Using not Evil, you can save time and keep total anonymity.
This search engine was formerly known as TorSearch.
Start Page
Startpage was made available in the year 2009. This name was chosen to make it easier for people to spell and remember.
Startpage.com and Ixquick.com are both the same and run by one company. It is a private search engine and offers the same level of protection.
This is one of the best search engines for concealing privacy. Unlike popular search engines, Startpage.com does not record your IP and keeps your search history a secret.
Related Dark Web Sources
Cyber Criminals are selling Hacking Tools on the Dark Web
617 Million Stolen Accounts For ‘Clearance Sale’ In The DarkWeb
Facebook Logins are Available on the Dark Web for $2.60
Tor Deep Web Search Engine – How to Download & use Tor Onion Browser Sites Safely (2023 Edition)
0 Comments